After my recent Internet speed
bump, the Cisco ASA 5505 I was using became
inmediately obsolete. It cannot handle more than 100 Mbps or so.

I’ve replaced it by the Fortigate 60D-WIFI. This is much more than a simple
router / firewall, it’s a Full UTM appliance. It
combines the usual router/firewall features with Antivirus, Intrusion
Prevention System, Data Leak Prevention, Web Filter and much more.
It has a nice web user interface to manage most of its features and the CLI
seems a lot easier to grasp than the CISCO.
So far I’m pretty happy with it.
However I found some gotchas:
PPPoE connection is not hardware accelerated
Even being in contact with Fortinet support, this one took a few weeks to
diagnose.
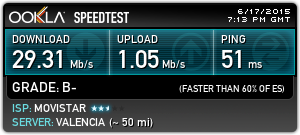
Testing the internet speed with speedtest.net or downloading multiple files, I
wasn’t able to reach 300 Mbps. In fact, it was aroud 180-190 Mbps.
The CPU in the Fortigate was 100% and became unresponsive while downloading.
It seems that this model doesn’t hardware accelerate PPPoE connections and all
the traffic is handled by the CPU.
PPPoE is the only connection type my ISP allows, so changing to something else
was not an option.
I solved it by keeping the ISP router and put the 60D in the DMZ of the ISP
router with a static IP assigned.
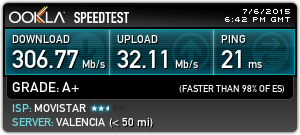
Now I can reach 300 Mbps with no impact on the CPU. However I have to keep
using the ISP router which I hoped to get rid of.
AP FAP21D radio 1 country GB (826) ==> US (841) set failed.
I also have an Fortinet Access Point 21D. I was getting this error message on
the logs. You are supposed to execute the following on the CLI:
config wireless-controller setting
set country ES
end
However I still was getting the same error. To solve it you have to delete all
the WIFI profiles, delete the FAP21 from the managed FortiAPs, make the
setting change and then add the FAP21 again.